
Auf dem Weg zu einem integrativen Modell der Informationskompetenzvermittlung (IMIK)
Das ACRL-Framework for Information Literacy for Higher Education und der aktivitäts- und eigenschaftsorientierte Datenlebenszyklus
Das ACRL-Framework for Information Literacy for Higher Education und der aktivitäts- und eigenschaftsorientierte Datenlebenszyklus
Zusammenfassung
Der Beitrag untersucht, inwieweit das ACRL-Framework for Information Literacy for Higher Education einen Beitrag zu einem integrativen Modell für die Vermittlung von Informations- und Datenkompetenzen leisten kann. Dazu werden die enthaltenen Kernelemente und Prinzipien vergleichend mit dem Modell des aktivitäts- und eigenschaftsorientierten Datenlebenszyklus betrachtet, der im Forschungsdatenmanagement und der Data Literacy den Forschungsprozess beschreibt. Basierend auf den Ergebnissen dieses Vergleichs werden die beiden Konzepte zu einem integrativen Modell der Informationskompetenzvermittlung (IMIK) synthetisiert, das durch den Datenlebenszyklus konkretisiert und ergänzt wird. Damit lassen sich Schulungsangebote zur Vermittlung von Informations- und Datenkompetenzen für verschiedene Zielgruppen und Niveaus ableiten, strukturieren, voneinander abgrenzen und den Agierenden aus den Fachwissenschaften und dem Infrastrukturbereich zuordnen.
Summary
This paper examines the possible contribution of the ACRL-Framework for Information Literacy for Higher Education to an integrated model for information and data literacy. For this, the core ideas and principles of the framework are compared to those of an activity and property driven data life cycle that describes the research process in research data management and data literacy. Based on the results of the comparison both concepts are synthesized into an Integrated Model for Information Literacy (IMIL), which is specified and supplemented by the data life cycle model. Applying IMIL, contents for courses in information and data literacy for different target audiences and levels can be developed, structured, differentiated and assigned to different stakeholders from science and infrastructure.
Dieses Werk steht unter der Lizenz Creative Commons Namensnennung 4.0 International.
1. Einleitung
Die Förderung digitaler Medien- und Informationskompetenz und das Management von Forschungsdaten stellen zentrale Handlungsfelder für wissenschaftliche Bibliotheken dar.1 Während sich die Vermittlung von Informationskompetenzen (IK-Vermittlung) als Kernaufgabe wissenschaftlicher Bibliotheken vielerorts weitgehend etabliert hat, stellt die Vermittlung von Kompetenzen im Rahmen des Forschungsdatenmanagements (FDM) und der Data Literacy (DL) oftmals eine neue Anforderung und zugleich Herausforderung für die Bibliothekswelt dar. Um dieser Aufgabe adäquat und dauerhaft gerecht werden zu können, bedarf es nachhaltiger Ressourcen, Infrastrukturen, Kooperationen sowie fachlicher Kompetenzen.
Zwar können Bibliotheken auf ein breites Spektrum an Schulungsangeboten zur IK-Vermittlung zurückgreifen, für die Vermittlung des FDM oder der DL müssen entsprechende Angebote aber oft erst noch entwickelt werden. Hierbei bietet es sich an, übergreifende Schulungsinhalte für die beiden Bereiche IK-Vermittlung einerseits und FDM bzw. DL andererseits zu identifizieren und zu integrieren mit dem Ziel, ein integratives Schulungsangebot bereitzustellen. Dabei sind Kooperationsmöglichkeiten unter Agierenden aus Infrastruktureinrichtungen und Fachwissenschaften auszuloten und sich bietende Synergien zu nutzen. Sowohl für die IK-Vermittlung als auch für das FDM bzw. die DL können zur Entwicklung von Schulungsangeboten zwei Wege beschritten werden: Der empirische Weg über Bedarfsermittlungen oder der theoretische Weg über Konzepte bzw. Modelle, der in der vorliegenden Arbeit verfolgt wird.
In der IK-Vermittlung haben sich insbesondere das Modell der Six Big Skills,2 das Modell des Information Search Process3 und das auf diesen Modellen basierende dynamische Modell der Informationskompetenz DYMIK4 etabliert. Hinzu kommen neuere Konzepte wie der Referenzrahmen Informationskompetenz des Deutschen Bibliotheksverbands5 und das ACRL-Framework for Information Literacy for Higher Education (ACRL-Framework)6. Zur Kompetenzvermittlung im FDM bzw. der DL können verschiedene Datenlebenszyklus-Modelle genutzt werden wie der Research Data Lifecycle des UK Data Service,7 das kompetenzbasierte Prozessmodell der Datenwertschöpfung8 oder der aktivitäts- und eigenschaftsorientierte Datenlebenszyklus (DLZ)9. In dem vorliegenden Artikel soll der Frage nachgegangen werden, inwieweit das ACRL-Framework zu einem integrativen Konzept für die Vermittlung von Informations- und Datenkompetenzen beitragen kann. Dazu wird das ACRL-Framework mit dem DLZ vergleichend betrachtet. Im Folgenden werden die Kernelemente und Prinzipien der beiden Konzepte erörtert, miteinander abgeglichen und die Ergebnisse des Abgleichs präsentiert.
2. Theoretische Konzepte der IK-Vermittlung und des FDM
2.1. Das ACRL-Framework in der IK-Vermittlung
Das ACRL-Framework adressiert in sechs Frames jeweils eines der folgenden Kernkonzepte der IK-Vermittlung zusammen mit einer Reihe von Wissenspraktiken und Dispositionen:
- Informationen schaffen als schöpferischer Prozess
- Forschung als Hinterfragen
- Suche als strategische Erkundung
- Wissenschaft als Diskurs
- Autorität ist konstruiert und kontextbezogen
- Informationen haben Wert
Pädagogisch-didaktische Grundlage des ACRL-Framework bilden Schwellenkonzepte. Dabei handelt es sich um Lernschwellen, die Lernende überwinden müssen, um einen Lernfortschritt zu erzielen und zu einem umfassenderen Verständnis von Informationskompetenz zu gelangen10,11. Konkretisiert werden die Schwellenkonzepte in jedem Frame im Hinblick auf Studienanfänger*innen und Expert*innen. Eine weitere Grundlage des ACRL-Framework stellt das Konzept der Metaliteracy dar12. Demnach wird Informationskompetenz als übergreifendes Set von Kompetenzen der Lernenden aufgefasst, die gemeinsam in digitalen interaktiven Umgebungen Informationen konsumieren und produzieren. Metaliteracy umfasst insbesondere die kritische Selbstreflexion (Metakognition) der Lernenden, erfordert aber auch verhaltensbezogene, affektive und kognitive Eigenschaften.
Auf Basis des ACRL-Framework lässt sich ein informationsbasierter Forschungsprozess konstruieren. In dessen Fokus stehen Forschende als informationsproduzierende bzw. -konsumierende Vertreter*innen einer bestimmten Fachkultur und -praxis mit ihrem jeweiligen Informationsbedarf sowie ihren Wissenspraktiken und Dispositionen. Während die Wissenspraktiken kognitive Kompetenzen darstellen, die die Dimensionen Wissen und Fertigkeiten der Forschenden adressieren, beziehen sich die Dispositionen auf deren affektive, einstellungsbezogene oder wertende Fähigkeiten. Der Forschungsprozess ist nicht nur von Wissenspraktiken und Dispositionen der Forschenden gekennzeichnet, sondern auch von Informationseigenschaften. Beispiele hierfür sind die Vielfalt und Vielzahl von Informationsprodukten und Verbreitungswegen, Produktinhalte, -beschreibungen und Produktzugänglichkeit.
Beschreibung der Frames
Der Frame „Informationen schaffen als schöpferischer Prozess“ thematisiert die Informationserzeugung und -verbreitung als dynamischen, iterativen Prozess, der zu einer Vielfalt von Informationsprodukten und Verbreitungsmethoden führt. Zurückgeführt wird diese Vielfalt auf die der Produkterzeugung zugrunde liegenden Prozesse, die beim Abgleich des Informationsbedarfs mit dem jeweiligen Produkt zu berücksichtigen sind. Studienanfänger*innen erkennen allmählich die Bedeutung dieser Prozesse, wodurch sie Informationsprodukte zunehmend differenzierter mit ihrem eigenen Informationsbedarf abgleichen. Informationsprodukte und die ihnen zugrunde liegenden Erzeugungsprozesse bilden die Grundlage für die kritische Bewertung des Nutzens von Information durch Expert*innen.
Der Frame „Forschung als Hinterfragen“ adressiert Informationen sowohl als Grundlage als auch als Ergebnis des dynamisch-iterativen Prozesses, mit dem sich gesellschaftliche, berufliche, persönliche oder wissenschaftliche Fragestellungen beantworten lassen. Letztere bilden den Ausgangspunkt wissenschaftlicher Forschung, die sich als hypothesen- oder fragegetriebener, iterativer Prozess auffassen lässt und mittels informationsbasierter Entscheidungen und Handlungen auf die Beantwortung von Fragestellungen unterschiedlicher Komplexität abzielt. Dies beinhaltet einfache Fragen, die sich mit vorhandenem Wissen beantworten lassen, bis hin zu komplexen Forschungsfragen, deren Beantwortung fortschrittliche Untersuchungsmethoden und unterschiedliche Perspektiven erfordert. Während sich Studienanfänger*innen ein umfassendes Repertoire an Forschungsmethoden und Strategien aneignen, bearbeiten Expert*innen offene Forschungsfragen kritisch und dialoggetrieben mit ihrer Fachcommunity und erweitern damit das Wissen in ihrem Fachgebiet.
Wie aus dem Frame „Suche als strategische Erkundung“ hervorgeht, ist für die Beantwortung der Fragen zum einen die Informationssuche als nicht-linearer, iterativer und fragegetriebener Vorgang essenziell, der systematische und unsystematische Suchmethoden umfassen kann und potenziell relevante Informationsquellen und deren Zugangsmöglichkeiten identifiziert. Der kontextbezogene Suchvorgang und die kognitiven, affektiven und sozialen Fähigkeiten der Informationssuchenden beeinflussen sich dabei wechselseitig. Studienanfänger*innen beschränken ihre Suche oft auf eine begrenzte Anzahl von Quellen und Suchstrategien, während Expert*innen weitreichender und tiefgreifender mit Hilfe ausgewählter Strategien suchen.
Zum anderen spielt der fortwährende Diskurs zwischen Informationsproduzierenden und -konsumierenden zur Klärung wissenschaftlicher Fragestellungen eine gewichtige Rolle (vgl. Frame „Wissenschaft als Diskurs“). Diese betrachten und klären einzelne Fragestellungen gemeinschaftlich aus verschiedenen, sich im Laufe der Zeit verändernden Blickwinkeln und Interpretationen, woraus fortwährend neue Erkenntnisse und Entdeckungen resultieren. Zum Einstieg in den wissenschaftlichen Diskurs machen sich Studienanfänger*innen mit den Formen und Methoden des Diskurses in ihrem Fach vertraut. Expert*innen bringen sich aktiv in den Diskurs ein, indem sie viele, auch konkurrierende Perspektiven zur Lösung komplexer Probleme ergründen.
Im Frame „Autorität ist konstruiert und kontextbezogen“ wird deutlich, dass die Qualität von Informationen auf Basis des jeweiligen Informationsbedarfs und Nutzungskontextes bewertet wird. Für wissenschaftliche Informationen basiert diese Bewertung auf der Forschungsfrage und der jeweiligen Fachkultur und -praxis der Bewertenden. Expert*innen berücksichtigen bei der Informationsbewertung auch (noch) nicht etablierte Quellen in ihrem Fachgebiet und identifizieren neue Perspektiven und verschiedene Lehrmeinungen. Studienanfänger*innen bewerten alle Quellen kritisch anhand formaler und inhaltlicher Kriterien wie Herkunft, Kontext und Eignung für den eigenen Informationsbedarf.
Dass Information unterschiedliche Wertedimensionen aufweist, die in verschiedenen Anwendungskontexten zum Ausdruck kommen, ist Gegenstand des Frames „Informationen haben Wert“. Demnach wird die Informationserzeugung und -verbreitung durch rechtliche und sozioökonomische Interessen beeinflusst. Bei der Informationsvermarktung und dem Zugang zu Informationsquellen kommt die Bedeutung von Information als materielles Gut bzw. Handelsware zum Tragen, beim Publizieren oder der Informationsverwertung ihre Bedeutung als immaterielles, urheberrechtlich geschütztes Gut. Während Studienanfänger*innen ein Verständnis für die unterschiedlichen Wertedimensionen entwickeln, weisen Expert*innen ein ausgeprägtes Handlungsbewusstsein bezüglich aktueller, rechtlicher und sozioökonomischer Praktiken bei der Informationserzeugung und -nachnutzung auf und hinterfragen diese im Bedarfsfall kritisch.
2.2. Der aktivitäts- und eigenschaftsorientierte Datenlebenszyklus im FDM
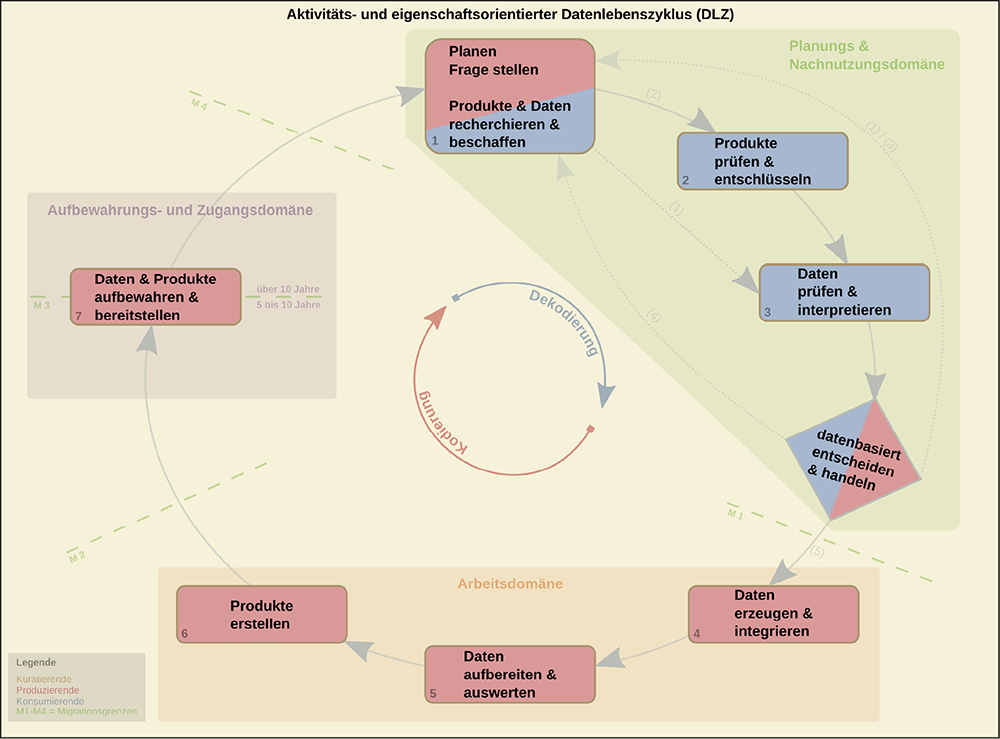
Ein Modell zur Ableitung von Schulungsangeboten im FDM stellt der aktivitäts- und eigenschaftsorientierte Datenlebenszyklus (DLZ) dar, der aus einer Synthese und Anpassung der drei Modelle „Research Data Life Cycle des UK Data Service“, „kompetenzbasiertes Prozessmodell der Datenwertschöpfung“ und „Modell des Data Curation Continuum“13 hervorgegangen ist (vgl. Abb. 1). Das Modell beschreibt den Forschungsprozess im Hinblick auf das Management von Forschungsdaten unter besonderer Berücksichtigung technischer, organisatorischer, rechtlicher und ethischer Aspekte. Dabei wird der Forschungsprozess als Kodierungs- bzw. Dekodierungsprozess von Daten wiedergegeben, in dem datenproduzierende bzw. -konsumierende Forschende kodierende bzw. dekodierende Aktivitäten ausüben und die neben Infrastruktureinrichtungen auch als Datenkuratierende auftreten. Da sich Aktivitäten und Dateneigenschaften wechselseitig beeinflussen, lässt sich der Prozess sowohl als zyklische Abfolge von Kernaktivitäten, den sog. Phasen, beschreiben als auch als Abfolge von Domänen mit sich ändernden Dateneigenschaften.
Die Aktivitätssicht
Der Forschungsprozess wird entweder von einer Hypothese bzw. Frage initiiert (hypothesengetriebener Forschungsansatz) oder er beginnt mit der Recherche und Beschaffung von Datenprodukten und/oder Daten, deren anschließender Prüfung und Interpretation mit Formulierung der Fragestellung (datengetriebener Forschungsansatz, vgl. Abb. 1, Verlauf 1). Zur Beantwortung der Ausgangsfrage werden verschiedene datenbasierte Entscheidungs- und Handlungsszenarien berücksichtigt (vgl. Abb. 1, Raute). Diese beinhalten die Aktivitäten Recherche und Beschaffung von Datenprodukten und/oder Daten, Prüfung und Entschlüsselung von Produkten, Datenprüfung und -interpretation inklusive Abgleich mit der Fragestellung. Damit lassen sich Entscheidungen im Hinblick auf die Verwendbarkeit vorhandener Produkte und Daten treffen, um die Frage zu beantworten. Entweder ist diese bereits beantwortet und muss neu formuliert werden (vgl. Abb. 1, Verlauf 3) oder die Beantwortung erfordert das Hinzuziehen zusätzlicher Produkte und Daten über weitere Recherche-, Beschaffungs- und Prüfschritte (vgl. Abb. 1, Verlauf 4). Alternativ lässt sich die Frage auch durch Synthese und Integration vorhandener und/oder gegebenenfalls neu zu erzeugender Daten beantworten (vgl. Abb. 1, Verlauf 5). Im weiteren Verlauf des Forschungsprozesses finden kodierende Aktivitäten statt, die sich über die zweite Zyklushälfte erstrecken: Von der Datenerzeugung und -integration, über deren Aufbereitung und Auswertung bis hin zur Erzeugung von Datenprodukten mit anschließender Aufbewahrung und nach Möglichkeit Bereitstellung von Daten und deren Produkten zur Nachnutzung für Dritte.
Die Eigenschaftssicht
Neben der hier beschriebenen Aktivitätssicht besteht das Modell aus einer Dateneigenschaftssicht, in deren Fokus das Datenobjekt mit seinen Eigenschaften steht. Sie trägt den technischen Aspekten des FDM Rechnung wie Infrastrukturen, mit denen Forschungsdaten verarbeitet, (langfristig) gesichert und bereitgestellt werden. Das Modell adressiert objektbezogene Dateneigenschaften, z.B. Datenvolumen, -formate, Metadaten, statische und dynamische Objektinhalte. Zugänglichkeit, Auffindbarkeit, Datensicherheit als zugangsbezogene Dateneigenschaften fließen ebenfalls in das Modell ein. Berücksichtigt werden zudem Managementkriterien wie die Zuständigkeit für das Datenmanagement und die Festlegung des Aufbewahrungszeitraums. In der Eigenschaftssicht ändern sich die Dateneigenschaften entlang des Forschungsprozesses mit den datenmanipulierenden Aktivitäten der Forschenden und Infrastruktureinrichtungen. Damit lassen sich die Dateneigenschaften zu drei eigenschaftsspezifischen Domänen mit zyklischer Anordnung gruppieren und die Phasen aus der Aktivitätssicht den jeweiligen Domänen zuordnen. Die Planungs- und Nachnutzungsdomäne ist durch eine Vielzahl und Vielfalt an (statischen) Datenprodukten und -objekten, großen Datenvolumina und (umfassenden, standardisierten) Metadaten gekennzeichnet und fällt mit den dekodierenden Phasen der Aktivitätssicht zusammen. Die kodierenden Aktivitäten entfallen auf die Arbeits- bzw. Aufbewahrungs- und Zugangsdomäne. Während erstere eine Vielzahl digitaler dynamischer Objekte in verschiedenen Versionen und wenige heterogene Metadaten beinhaltet, zeichnet sich letztere durch eine verringerte Anzahl an statischen Datenobjekten und -produkten mit umfassenden, standardisierten Metadaten und einem verringerten Datenvolumen aus. Die Zuständigkeit für die Datenkuratierung geht von den Forschenden in der Planungs- und Nachnutzungsdomäne bzw. Arbeitsdomäne über auf die Infrastruktureinrichtungen in der Aufbewahrungs- und Zugangsdomäne. Dabei wird der Zugang zu den Daten über die drei Domänen hinweg zunehmend kontrolliert ausgeweitet vom einzelnen Forschenden, über das Projektteam bis hin zu nachnutzenden (forschenden) Dritten. Die Änderungen der Dateneigenschaften erfolgen an Migrationsgrenzen, die in ihrer Abfolge mit den Domänen alternieren und an denen Datenselektion, Formatkonversion, Anreicherung mit Metadaten und Migration stattfinden.
3. Vergleichende Betrachtung des ACRL-Framework und des aktivitäts- und eigenschaftsorientierten Datenlebenszyklus
3.1. Abgleich der Kernelemente und Prinzipien
Beide Konzepte beschreiben einen informations- bzw. datenbasierten, dynamisch-iterativen Forschungsprozess und unterscheiden zwischen Produkten und zugrunde liegenden Prozessen der Produkterzeugung. Im DLZ werden Informationen in Form von Datenprodukten thematisiert, die verschiedene Formen von Daten repräsentieren (Diagramme, Datensätze, Tabellen, Studien etc.). Informationen entstehen aus Daten, die in einen Kontext bzw. eine Beziehung zueinander gesetzt werden. Das ACRL-Framework bezieht sich auf Informationen in beliebigen Darstellungsformen, den Informationsprodukten. Dazu gehören beispielweise Bücher, Aufsätze, Datenprodukte. Der iterative Prozesscharakter wird im DLZ über die zyklische Abfolge von Kernaktivitäten (Phasen) bzw. Domänen mit datenmanipulierenden Aktivitäten und veränderten Dateneigenschaften verdeutlicht. Im ACRL-Framework lassen sich die Wissenspraktiken über die Frames hinweg inhaltlich zu fünf Phasen bzw. Kernaktivitäten bündeln und den Phasen des DLZ zuordnen, woraus ein zyklisches und damit iteratives IK-Modell abgeleitet werden kann (vgl. Tabelle 1). Aus dem Abgleich der beiden Modelle geht hervor, dass es sich bei den Kernaktivitäten bzw. Phasen des IK-Modells um dekodierende bzw. kodierende Phasen handelt, die sich auf dekodierende bzw. kodierende Agierende beziehen: informationskonsumierende Forschende bzw. informationsproduzierende Forschende. Dabei wird auch ersichtlich, dass die Informationssuche und -beschaffung eine eigene Phase im IK-Modell bildet, während die Phasen Informationsprüfung, -interpretation und -bewertung sowie Informationserzeugung in mehrere Phasen des DLZ auffächern (vgl. Tabelle 1).

Im Gegensatz zum DLZ fokussiert das IK-Modell auf die Wissenspraktiken bzw. kognitiven Kompetenzen (Wissen, Fertigkeiten) und Dispositionen der Forschenden unter besonderer Berücksichtigung ihrer Fachkulturen und -praktiken, die im gesamten Prozess zum Tragen kommen. Beide Modelle adressieren sowohl organisatorische als auch rechtliche und ethische Aspekte entlang des Forschungsprozesses. Sozioökonomische Rahmenbedingungen werden explizit im IK-Modell bei der Informationsbeschaffung, -erzeugung und -verbreitung berücksichtigt. Für die rechtlichen und sozioökonomischen Aspekte greift in der IK-Vermittlung ein Schwellenkonzept, das auf den materiellen und immateriellen Wert von Information abzielt (vgl. Frame „Informationen haben Wert“). Dieses Konzept findet sich analog in der DL bzw. dem FDM wieder: Während Studienanfänger*innen ein Verständnis für die unterschiedlichen Wertedimensionen von Informationen (Datenprodukten) bzw. Daten entwickeln, nutzen Expert*innen dieses Verständnis zu deren Erzeugung und Nachnutzung.
- Zur Entscheidung darüber, ob Daten für den Forschungsprozess beschafft oder neu erzeugt werden sollen, benötigen Forschende im FDM auch ein Verständnis über die mit der Datenerzeugung verbundenen Kosten und die Nutzungsrechte von Daten (Lizenzen).
- Damit Forschende im FDM ihre erzeugten Daten vermarkten bzw. zur Nachnutzung bereitstellen können, benötigen sie ein Verständnis über die beim Forschungsprozess anfallenden Kosten und ihre Rechte und Pflichten als Urheber.
Abgleich dekodierender Phasen des IK-Modells und des DLZ
Die dekodierenden Phasen des IK-Modells enthalten alle Kernaktivitäten des Forschungsprozesses mit Ausnahme der Prozessplanung. Analog zum DLZ wird im IK-Modell der fragegetriebene und informationsbasierte Ansatz berücksichtigt: Formulierung von „Forschungsfragen auf der Grundlage von Informationslücken oder durch erneute Untersuchung bereits existierender und möglicherweise sich widersprechender Informationen“14. Der Phase „Thema, Frage eingrenzen“ des IK-Modells liegt eine Lernschwelle zugrunde, die sich auf das FDM bzw. die DL übertragen lässt: Während Studienanfänger*innen einfache Forschungsfragen zum Wissenserwerb beantworten, indem sie z.B. Re-Analysen mit vorhandenen Schulungsdatensätzen durchführen oder Datenprodukte interpretieren, generieren Expert*innen neue Informationen aus vorhandenen Datenprodukten bzw. Daten und/oder neu erzeugten Daten zur Beantwortung offener, komplexer Forschungsfragen und tragen damit zur Wissenserweiterung in ihrem Fachgebiet bei.
Der Beantwortung von Fragestellungen geht in der IK-Vermittlung die Phase der Suche nach Informationen voraus, bei der ebenfalls eine Lernschwelle überwunden werden muss. Analoges gilt auch für die DL bzw. das FDM: Auf der Suche nach Datenprodukten bzw. Daten machen Studienanfänger*innen von einer begrenzten Anzahl von Quellen und Suchstrategien Gebrauch, wohingegen Expert*innen weiterführende Quellen in die Suche einbeziehen und vertiefter und differenzierter suchen.
- Studienanfänger*innen durchsuchen homogene Quellen wie Faktendatenbanken oder Forschungsdatenrepositorien. Expert*innen erweitern ihre Suche auf heterogene Quellen wie integrierte Literatur- und Faktendatenbanken mit Verlinkung zu Forschungsdatenarchiven15.
Berücksichtigt wird in beiden Modellen das informations- bzw. datenbasierte Entscheiden und Handeln. Im IK-Modell kommt es zum Tragen beim Ableiten logischer Schlussfolgerungen aus Informationsanalysen und bei der Informationsauswahl, die sich auf die Anwendungszwecke und die Kernaussagen des aus den Informationen generierten Produkts auswirkt: Studienanfänger*innen bzw. Expert*innen „entwickeln – wenn sie selbst Informationen erstellen – ein Verständnis dafür, dass ihre Wahl den Verwendungszweck des Informationsproduktes sowie die Nachricht beeinflusst, die es übermittelt“16. Für die Informationsauswahl ist die Informationsbewertung entscheidend, die Studienanfänger*innen anhand formaler und inhaltlicher Kriterien vornehmen und die Expert*innen auf nicht etablierte Quellen ausweiten und dabei neue Perspektiven und verschiedene Lehrmeinungen identifizieren. Diese Lernschwelle existiert analog in der DL bzw. im FDM, wo Datenprodukte bzw. Daten ebenfalls anhand formaler und inhaltlicher Kriterien geprüft, interpretiert und bewertet werden.
- Studienanfänger*innen im FDM prüfen und bewerten die Datenqualität anhand formaler und inhaltlicher Kriterien für die anschließende Datenauswahl, während Expert*innen den Mehrwert von Daten für andere Fragestellungen aus demselben oder einem anderen, auch fachfremden Forschungskontext erkennen.
Abgleich kodierender Phasen des IK-Modells und des DLZ
Bei den kodierenden Phasen fokussiert das IK-Modell zum einen auf die Informationserzeugung, wobei die Erstellung von Informationsprodukten in verschiedenen Formaten im Vordergrund steht. Zum anderen liegt der Fokus auf der Informationsverbreitung mit dem wissenschaftlichen Diskurs als zentralem Verbreitungsprozess. Neben der Erzeugung von Daten betrachtet der DLZ die Erstellung von Datenprodukten mit der vorgeschalteten Datenaufbereitung und -auswertung. Der DLZ geht nicht dezidiert auf die Verbreitung von Daten und den daraus resultierenden Datenprodukten im Sinne eines wissenschaftlichen Diskurses ein, sondern auf deren Aufbewahrung und Bereitstellung. Die kritische Bewertung des Nutzens von Information für einen bestimmten Bedarf setzt voraus, dass ein kritischer Abgleich des Bedarfs mit dem jeweiligen Informationsprodukt durchgeführt wird. Dazu müssen die Prozesse, die der Erzeugung von Informationsprodukten zugrunde liegen, erkannt werden. Analoges trifft auch zu auf die Erzeugung von Datenprodukten und von Daten.
- Im FDM bzw. der DL liegen je nach Forschungsgegenstand und -methode verschiedene Datentypen vor, aus denen unterschiedliche Datenprodukte resultieren. Man unterscheidet beispielsweise quantitative, numerische Daten, die man aus der Messung von Substanzproben erhält, von qualitativen Daten aus Personenbefragungen (z.B. Audio- bzw. Videointerviews). Adäquate Darstellungsformen für numerische Daten können Tabellen, Diagramme, Graphen sein und für qualitative Daten Studien in Textform.
- In der DL sind Datenprodukte auf die zugrunde liegenden Daten zurückzuführen und deren Darstellung in Form von Diagrammen, Datentabellen oder auch Studien nachzuvollziehen. Werden die beschriebenen Prozesse erkannt bzw. nachvollzogen, lässt sich der Nutzen von Daten bzw. Datenprodukten für einen bestimmten Bedarf kritisch bewerten.
Abgleich der Eigenschaften von Informations- und Datenobjekten
Der Forschungsprozess wird in beiden Modellen nicht nur über Kernaktivitäten, sondern auch über objektbezogene und zugangsbezogene Eigenschaften von Informations- bzw. Datenobjekten charakterisiert. Im IK-Modell macht sich dies bemerkbar in der Vielzahl verschiedener Informationsobjekte, die sich in ihren statischen bzw. dynamischen Inhalten, formellen oder informellen Beschreibungen und ihrer Zugänglichkeit unterscheiden. Damit lässt sich ein Bezug zum DLZ herstellen, der diese Eigenschaften für Datenobjekte konkretisiert. Formelle Beschreibungen in Form umfassender, standardisierter Metadaten sind mit statischen Objekten verbunden, deren Anzahl und Vielfalt sich von der Planungs- und Nachnutzungsdomäne hin zur Aufbewahrungs- und Zugangsdomäne deutlich reduziert. Dagegen sind die vielen verschiedenen dynamischen Objekte in der Arbeitsdomäne informell mit wenigen heterogenen Metadaten ausgezeichnet. Die Zugänglichkeit der Objekte weitet sich über die Domänen hinweg zunehmend aus, von eingeschränkt bis hin zu kontrolliert oder offen zugänglichen Objekten.
3.2. Ableitung eines integrativen Modells der Informationskompetenzvermittlung (IMIK)
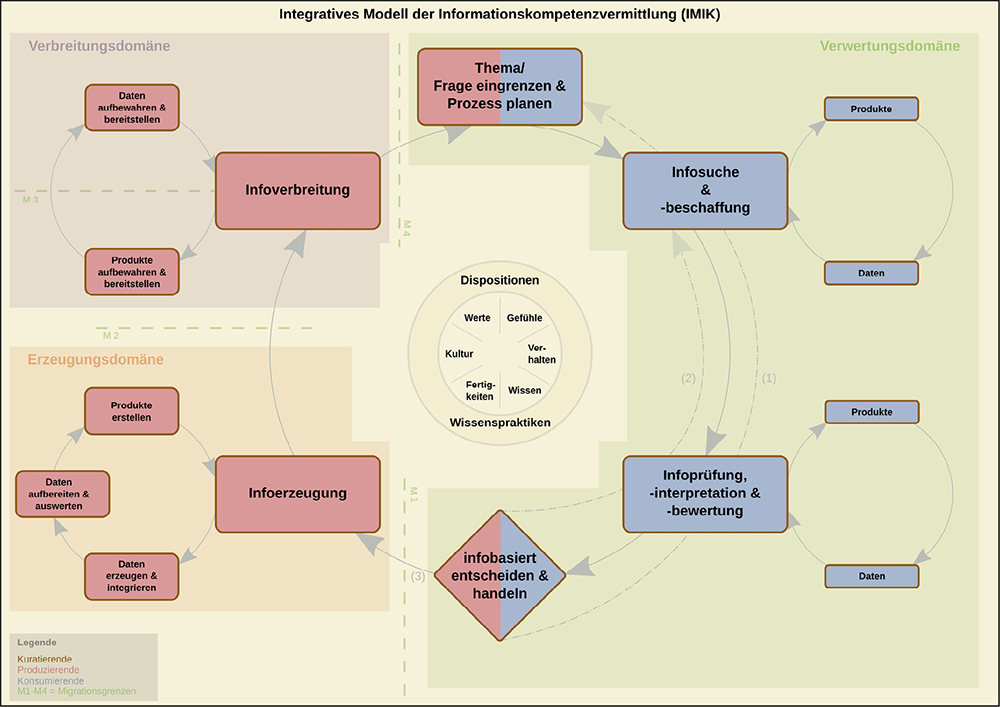
Auf Basis des Modellabgleichs lassen sich beide Modelle zu einem integrativen Modell der Informationskompetenzvermittlung kombinieren, das die Kernelemente und Prinzipien der beiden einzelnen Modelle vereint (vgl. Abb. 2). Über das IK-Modell wird die Informationssuche und -beschaffung als eigene Phase berücksichtigt und die Informationsverbreitung über den wissenschaftlichen Diskurs ins Modell eingeführt. Mit den Wissenspraktiken, Dispositionen, der Fachkultur und -praxis der Forschenden, den Schwellenkonzepten und dem Konzept der Metaliteracy als zentralen Elementen trägt das IK-Modell wesentlich zum integrativen Modell bei. Umgekehrt profitiert das integrative Modell vom DLZ. Zum einen findet die Prozessplanung Eingang ins integrative Modell. Zum anderen werden neben den Informationseigenschaften auch die Modellphasen wie folgt konkretisiert: Die Phase der Informationsprüfung, -interpretation und -bewertung kann sich sowohl auf Information als auch auf Daten beziehen. Die Phase der Informationserzeugung wird um die Datenerzeugung und -integration, Datenaufbereitung und -auswertung ergänzt. Die Phase der Informationsverbreitung wird erweitert um die zugrunde liegenden Prozesse der Aufbewahrung und Bereitstellung von Informationen und Daten.
Modellbeschreibung
Das integrative Modell umfasst eine Aktivitäts- und eine Eigenschaftssicht. Im Mittelpunkt des Modells stehen die informationsproduzierenden bzw. -konsumierenden und zugleich kuratierenden Forschenden mit ihrem jeweiligen Informationsbedarf, ihrer Fachkultur und -praxis und ihren Wissenspraktiken bzw. kognitiven Kompetenzen (Wissen, Fertigkeiten) und Dispositionen (affektive, einstellungsbezogene oder wertende Fähigkeiten) sowie verhaltensbezogenen Eigenschaften. Bei den über den gesamten Forschungsprozess anfallenden kuratierenden Tätigkeiten können sie sich von Infrastruktureinrichtungen unterstützen lassen und dabei insbesondere die Zuständigkeit für die langfristige Aufbewahrung von Informationen und Daten und deren Verbreitung an Infrastruktureinrichtungen abgeben.
Die Aktivitätssicht
Das Modell beschreibt den informationsbasierten Forschungsprozess als zyklische Abfolge von fünf Hauptphasen (vgl. Abb. 2, Rechtecke), die in einer dekodierenden und kodierenden Zyklushälfte ausgewogen angeordnet sind und beginnt mit der Absteckung des Forschungsthemas, einer grob formulierten Forschungsfrage bzw. Hypothese sowie der Forschungsplanung. Durch die nachgeschaltete Informationssuche und -beschaffung mit anschließender Prüfung und Bewertung wird das Thema konkretisiert und die Frage zunehmend präzisiert (vgl. Abb. 2, Verlauf 1). Über das Modellelement informationsbasiertes Entscheiden und Handeln (vgl. Abb. 2, Raute) werden nicht nur die beiden Zyklushälften miteinander verbunden, sondern auch verschiedene Entscheidungs- und Handlungsoptionen in Bezug auf die Beantwortung der Forschungsfrage eröffnet. Neben der Präzisierung oder Umformulierung der Forschungsfrage (Abb. 2, Verlauf 1) können hierfür im Bedarfsfalle zusätzliche Informationen bzw. Daten über erneute Such-, Beschaffungs- und Prüfvorgänge herangezogen werden (Abb. 2, Verlauf 2) oder die vorhandenen Informationen bzw. Daten werden ggf. auch mit neu erzeugten synthetisiert und integriert (vgl. Abb. 2, Verlauf 3). Damit wird auch dem dynamisch-iterativen und rekursiven Charakter des informations- bzw. datenbasierten Forschungsprozesses Rechnung getragen. Allen Phasen mit Ausnahme der Anfangsphase liegen Prozesse zugrunde, die sich als Abfolge von Unterphasen darstellen lassen. Das Suchen und Beschaffen sowie das Prüfen, Interpretieren und Bewerten kann sich sowohl auf Informationen als auch auf Daten beziehen. Bei der Informationserzeugung werden Informationen aus Daten erstellt und bei der Informationsverbreitung wird zwischen der Aufbewahrung und Bereitstellung von Informationen bzw. Daten unterschieden.
Die Eigenschaftssicht
Die Gruppierung der Haupt- und Unterphasen in Domänen einer Eigenschaftssicht ermöglicht die Einführung von Informations- bzw. Dateneigenschaften ins Modell und deren Verknüpfung mit den Aktivitäten des Forschungsprozesses. In der Verwertungsdomäne werden Informationen bzw. Daten recherchiert, beschafft, geprüft, interpretiert und mit der Forschungsfrage abgeglichen, sodass eine Vielzahl und Vielfalt (statischer) Informations- bzw. Datenobjekte mit (umfassenden, standardisierten) Metadaten vorliegt. Die anschließende Informations- bzw. Datenverarbeitung, -auswertung und Produkterstellung erfolgt in der Erzeugungsdomäne, die sich durch viele dynamische Objekte in verschiedenen Versionen und durch wenige, heterogene Metadaten auszeichnet. Die Verbreitungsdomäne enthält eine im Vergleich zur Verwertungsdomäne deutlich reduzierte Anzahl statischer Informations- bzw. Datenobjekte mit umfassenden, standardisierten Metadaten, die langfristig aufbewahrt und der Forschungscommunity für den wissenschaftlichen Diskurs und zur Nachnutzung bereitgestellt werden. An den Migrationsgrenzen werden Informations- bzw. Datenobjekte selektiert und deren Formate konvertiert, mit Metadaten angereichert und migriert. Weitere Eigenschaften der Informations- bzw. Datenobjekte wie Volumen, Metadatentypen, Auffindbarkeit, Sicherheit und Managementkriterien wie Zuständigkeit für das Informations- bzw. Datenmanagement und die Festlegung des Aufbewahrungszeitraums fließen über das Modell des DLZ in das integrative Modell mit ein.
Ableitung von Trainingsangeboten
Die dem Modell inhärenten Wissenspraktiken bzw. wissensbasierten Kompetenzen und Dispositionen ermöglichen die Ableitung von Lehrinhalten und Lernzielen, die mit Hilfe der Schwellenkonzepte für die verschiedenen Zielgruppen aus IK-Vermittlung, FDM und DL nach Anfänger- und Fortgeschrittenenniveau differenziert werden können. Die Lehrinhalte und Lernziele lassen sich den Phasen von IMIK zuordnen. Dies erleichtert deren Strukturierung, gegenseitige Abgrenzung und die Aufteilung unter den Agierenden aus den Fachwissenschaften und dem Infrastrukturbereich, die mit der Kompetenzvermittlung auf diesen Gebieten betraut sind. Beispielweise könnten die Fachwissenschaften Lehrinhalte zur Forschungsmethodik vermitteln. Rechenzentren und Bibliotheken wären aufgrund ihrer Expertise für die Vermittlung von Kompetenzen zum Informations- bzw. Datenmanagement und zu Infrastrukturen prädestiniert, Schreibzentren oder Medienkompetenzzentren für die Erstellung und Gestaltung von Informations- bzw. Datenprodukten. Einen ersten Eindruck für die Ausgestaltung von Trainingsangeboten mit Hilfe von Lernschwellen vermitteln die Beispiele aus der Forschungspraxis in Kapitel 3.1.
4. Fazit
In der vorliegenden Arbeit werden die Kernelemente und Prinzipien des ACRL-Framework mit denen des aktivitäts- und eigenschaftsorientierten Datenlebenszyklus (DLZ) zu einem integrativen Modell der Informationskompetenzvermittlung (IMIK) vereint, das sich durch folgende Merkmale auszeichnet: Der Forschungsprozess wird als fragegetriebener Informationserzeugungs- und Verbreitungsprozess beschrieben, der sich auf wenige Kernaktivitäten bzw. Phasen reduzieren lässt und durch wesentliche Informationseigenschaften charakterisiert ist. Besondere Bedeutung kommen der Informationssuche und -beschaffung als eigener Phase zu sowie den Prozessen, die der Produkterzeugung zugrunde liegen und die zu einer Vielzahl und Vielfalt an Produkten führen. Der dynamisch-iterative Prozesscharakter und die Aktivitätsorientierung werden durch die zyklische Abfolge der Phasen wiedergegeben, der rekursive, nicht-lineare Charakter der Frageformulierung bzw. -präzisierung, der Informationssuche und -beschaffung mit anschließender Prüfung und Bewertung durch das Modellelement des informationsbasierten Entscheidens und Handelns. Zugleich trägt dieses Element verschiedenen Entscheidungs- und Handlungsszenarien bezüglich der Beantwortung der Forschungsfrage Rechnung. Über das Konzept der Metaliteracy werden informationskonsumierende und -produzierende Forschende mit ihrem jeweiligen Informationsbedarf, ihrer Fachkultur und -praxis, ihren Wissenspraktiken und Dispositionen ins Zentrum des Prozesses gerückt. Gemeinsam konsumieren, erzeugen und teilen sie Informationen zur Klärung wissenschaftlicher Fragestellungen, wobei der Diskurs eine zentrale Rolle spielt. Mit den Kernaktivitäten, Produkteigenschaften und dem Konzept der Metaliteracy wird die Verbindung zum DLZ hergestellt, der im FDM u.a. zur Vermittlung von Datenkompetenzen Anwendung findet. Über dieses Modell lässt sich zudem das Prinzip der Kodierung und Dekodierung auf die Agierenden und Phasen des IK-Modells übertragen. Die Phasen und Informationseigenschaften lassen sich konkretisieren und ergänzen und zu Domänen mit spezifischen Eigenschaften und Aktivitäten gruppieren, sodass ein integratives Modell der Informationskompetenzvermittlung entsteht.
Dieses Modell ist den beiden zugrunde liegenden Modellen in zweifacher Hinsicht überlegen: Die auf den DLZ zurückgehende Konkretisierung der einzelnen Modellphasen und Informationseigenschaften eröffnet der Informationskompetenzvermittlung ein vertieftes Verständnis des Forschungsprozesses. Kernaktivitäten wie Informationssuche und -beschaffung, Informationsprüfung, -erzeugung und -verbreitung lassen sich damit effizienter und effektiver bewerkstelligen und deren Qualität steigern. Das FDM bzw. die DL profitieren hingegen von den aus dem IK-Modell stammenden Wissenspraktiken, Dispositionen, Fachkulturen und -praktiken sowie den Schwellenkonzepten und dem Konzept der Metaliteracy. Mit Hilfe des integrativen Modells lassen sich Lerninhalte und Lernziele für verschiedene Zielgruppen und Niveaus ableiten, strukturieren, voneinander abgrenzen und den mit der Kompetenzvermittlung befassten Agierenden aus Wissenschaft und Infrastruktur zuordnen.
Literaturverzeichnis
- Association of College and Research Libraries (ACRL): Framework for Information Literacy for Higher Education, ala.org, 11.01.2016, <http://www.ala.org/acrl/sites/ala.org.acrl/files/content/issues/infolit/framework1.pdf>, Stand: 04.12.2020.
- Klingenberg, Andreas: Referenzrahmen Informationskompetenz. Erarbeitet von Andreas Klingenberg im Auftrag der dbv-Kommission Bibliothek & Schule und der Gemeinsamen Kommission Informationskompetenz von VDB und dbv, bibliotheksverband.de, 2016, <https://www.bibliotheksverband.de/fileadmin/user_upload/Kommissionen/Kom_Infokompetenz/2016_11_neu_Referenzrahmen-Informationskompetenz_endg__2__Kbg.pdf>, Stand: 04.12.2020.
- Deutscher Bibliotheksverband e.V.: Wissenschaftliche Bibliotheken 2025, bibliotheksverband.de, Januar 2018, <https://www.bibliotheksverband.de/fileadmin/user_upload/Sektionen/sektion4/Publikationen/WB2025_Endfassung_endg.pdf>, Stand: 04.12.2020.
- Homann, Benno: Das Dynamische Modell der Informationskompetenz (DYMIK). Didaktisch-methodische Grundlage für die Vermittlung von Methodenkompetenz an der UB Heidelberg, Theke. Informationsblatt der Mitarbeiterinnen und Mitarbeiter im Bibliothekssystem der Universität Heidelberg, 2000, S. 86-93, <https://www.ub.uni-heidelberg.de/schulung/schulungskonzept/DYMIK.pdf>, Stand: 04.12.2020.
- Kuhlthau, Carol: Information Search Process, Rutgers. School of Communication and Information, <http://wp.comminfo.rutgers.edu/ckuhlthau/information-search-process/>, Stand: 04.12.2020.
- Mackey, Thomas P.; Jacobson, Trudi E.: Reframing Information Literacy as a Metaliteracy, in: College and Research Libraries 72 (1), 2011, <https://crl.acrl.org/index.php/crl/article/view/16132/17578>, Stand: 04.12.2020.
- Meyer, Jan; Land, Ray: Threshold Concepts and Troublesome Knowledge. Linkages to Ways of Thinking and Practising within the Disciplines, in: ETL Project Reports, Occassional Report 4, 2003, <http://www.etl.tla.ed.ac.uk/docs/ETLreport4.pdf>, Stand: 04.12.2020.
- Schüller, Katharina; Busch, Paulina; Hindinger, Carina: Future Skills: Ein Framework für Data Literacy, Hochschulforum Digitalisierung Nr. 47, Zenodo, 05.09.2019, <https://doi.org/10.5281/zenodo.3349864>.
- The Big 6, <https://thebig6.org/>, Stand: 04.12.2020.
- Townsend, Lori; Hofer, Amy R.; Hanick, Silvia L.; Brunetti, Korey: Identifying Threshold Concepts for Information Literacy. A Delphi Study, in: Communications in Information Literacy, 10 (1), 2016, S. 23-49, <https://doi.org/10.15760/comminfolit.2016.10.1.13>.
- Treloar, Andrew; Harboe-Ree, Cathrine: Data management and the curation continuum: how the Monash experience is informing repository relationships, in: VALA (6), 05.02.2008, <https://www.vala.org.au/vala2008-proceedings/vala2008-session-6-treloar>, Stand: 04.12.2020.
- UK Data Service: Research data lifecycle, ukdataservice.ac.uk, <https://www.ukdataservice.ac.uk/manage-data/lifecycle.aspx>, Stand: 04.12.2020.
- Wolf, Armin Harry; Leppla, Cindy: Harmonisierung von Datenlebenszyklus-Modellen. Nutzung von Synergien für optimierte Anwendungen im FDM, in: Bausteine Forschungsdatenmanagement. Empfehlungen und Erfahrungsberichte für die Praxis von Forschungsdatenmanagerinnen und -managern 2 (November), 2020, S. 1-19, <https://doi.org/10.17192/bfdm.2020.2.8281>.
1 Deutscher Bibliotheksverband e.V.: Wissenschaftliche Bibliotheken 2025, bibliotheksverband.de, Januar 2018, <https://www.bibliotheksverband.de/fileadmin/user_upload/Sektionen/sektion4/Publikationen/WB2025_Endfassung_endg.pdf>, Stand: 04.12.2020.
2 The Big 6, <https://thebig6.org/>, Stand: 04.12.2020.
3 Kuhlthau, Carol: Information Search Process, Rutgers. School of Communication and Information, <http://wp.comminfo.rutgers.edu/ckuhlthau/information-search-process/>, Stand: 04.12.2020.
4 Homann, Benno: Das Dynamische Modell der Informationskompetenz (DYMIK). Didaktisch-methodische Grundlage für die Vermittlung von Methodenkompetenz an der UB Heidelberg, Theke. Informationsblatt der Mitarbeiterinnen und Mitarbeiter im Bibliothekssystem der Universität Heidelberg, 2000, S. 86-93, <https://www.ub.uni-heidelberg.de/schulung/schulungskonzept/DYMIK.pdf>, Stand: 04.12.2020.
5 Klingenberg, Andreas: Referenzrahmen Informationskompetenz. Erarbeitet von Andreas Klingenberg im Auftrag der dbv-Kommission Bibliothek & Schule und der Gemeinsamen Kommission Informationskompetenz von VDB und dbv, bibliotheksverband.de, 2016, <https://www.bibliotheksverband.de/fileadmin/user_upload/Kommissionen/Kom_Infokompetenz/2016_11_neu_Referenzrahmen-Informationskompetenz_endg__2__Kbg.pdf>, Stand: 04.12.2020.
6 Association of College and Research Libraries (ACRL): Framework for Information Literacy for Higher Education, ala.org, 11.01.2016, <http://www.ala.org/acrl/sites/ala.org.acrl/files/content/issues/infolit/framework1.pdf>, Stand: 04.12.2020. Für die deutsche Übersetzung des Frameworks vgl.: Association of College and Research Libraries (ACRL): Framework Informationskompetenz in der Hochschulbildung, übersetzt durch Gemeinsame Kommission Informationskompetenz von dbv und VDB, in: o-bib. Das offene Bibliotheksjournal 8 (2), 2021, S. 1-29, <https://doi.org/10.5282/o-bib/5674>
7 UK Data Service: Research data lifecycle, ukdataservice.ac.uk, <https://www.ukdataservice.ac.uk/manage-data/lifecycle.aspx>, Stand: 04.12.2020.
8 Schüller, Katharina; Busch, Paulina; Hindinger, Carina: Future Skills: Ein Framework für Data Literacy, Hochschulforum Digitalisierung Nr. 47, Zenodo, 05.09.2019, <https://doi.org/10.5281/zenodo.3349864>.
9 Wolf, Armin Harry; Leppla, Cindy: Harmonisierung von Datenlebenszyklus-Modellen. Nutzung von Synergien für optimierte Anwendungen im FDM, in: Bausteine Forschungsdatenmanagement. Empfehlungen und Erfahrungsberichte für die Praxis von Forschungsdatenmanagerinnen und -managern 2 (November), 2020, S. 1-19, https://doi.org/10.17192/bfdm.2020.2.8281.
10 Meyer, Jan; Land, Ray: Threshold Concepts and Troublesome Knowledge. Linkages to Ways of Thinking and Practising within the Disciplines, in: ETL Project Reports, Occassional Report 4, 2003, <http://www.etl.tla.ed.ac.uk/docs/ETLreport4.pdf>, Stand: 04.12.2020.
11 Townsend, Lori; Hofer, Amy R.; Hanick, Silvia L.; Brunetti, Korey: Identifying Threshold Concepts for Information Literacy. A Delphi Study, in: Communications in Information Literacy, 10 (1), 2016, S. 23-49, <https://doi.org/10.15760/comminfolit.2016.10.1.13>.
12 Mackey, Thomas P.; Jacobson, Trudi E.: Reframing Information Literacy as a Metaliteracy, in: College and Research Libraries 72 (1), 2011, <https://crl.acrl.org/index.php/crl/article/view/16132/17578>, Stand: 04.12.2020.
13 Treloar, Andrew; Harboe-Ree, Cathrine: Data management and the curation continuum: how the Monash experience is informing repository relationships, in: VALA (6), 05.02.2008, <https://www.vala.org.au/vala2008-proceedings/vala2008-session-6-treloar>, Stand: 04.12.2020.
14 Eine Wissenspraktik aus dem Frame „Forschung als Hinterfragen“. Vgl.: ACRL: Framework Informationskompetenz in der Hochschulbildung, 2021.
15 Das Fachportal für Pädagogik vom DIPF, Leibniz-Institut für Bildungsforschung und Bildungsinformation als zentraler Einstieg in die wissenschaftliche Fachinformation für Bildungsforschung, Erziehungswissenschaft und Fachdidaktik stellt hierfür ein fächerübergreifendes Beispiel dar. Fachportal Pädagogik, DIPF, <https://www.fachportal-paedagogik.de/>, Stand: 04.12.2020.
16 Eine Wissenspraktik aus dem Frame „Informationen schaffen als schöpferischer Prozess“. Vgl.: ACRL: Framework Informationskompetenz in der Hochschulbildung, 2021.
